





丁肇豪教授课题组在大语言模型碳足迹量化领域取得进展
信息发布于:2025-05-08
近年来,大语言模型的爆发式增长正在重塑社会生产力,但其在训练和推理过程中产生的庞大能源消耗引发了广泛的环境担忧。公开数据显示,仅GPT-3在训练阶段的电力消耗就高达1287MWh,大约相当于1000户普通中国家庭一年的耗电量。在“大模型热”的背景下,与GPT-3规模相当的大语言模型已超过75个。然而,当前科学界对于全球范围内大语言模型所引发的能耗与碳排放问题,仍缺乏系统的量化分析与深入预测。此外,各行业垂直领域大语言模型在实际应用中的能耗与环境影响亦尚不明晰。厘清上述问题可为大语言模型的爆发式增长与全球碳中和发展目标间的平衡提供科学支撑。
针对这些问题,丁肇豪教授课题组与北京大学、德克萨斯大学等高校研究者合作,通过分析2018至2024年间全球发布的369个大语言模型的生产运行数据,首次系统性为大语言模型的创造力估算环境成本,揭示了全球大语言模型碳排放的区域分布、行业特征以及未来发展路径,为优化人工智能算力布局与开源生态建设提供科学依据。主要得出以下三个核心发现:
1、大语言模型能耗与碳排现状:当前全球大语言模型的年耗电量达24.97-41.1 TWh,相当于中国三峡工程年发电量的40%,由此产生的二氧化碳排放量达1067万至1861万吨,最大碳排放量约占亚马逊雨林年固碳量的 3.6%。值得注意的是,99%的碳排放集中在中美两国——中国因相对较高的碳密度(0.544 kg/kWh)贡献了54.4%的排放量,美国则以更大规模的算力负载占据45.5%。相比之下,瑞典等低碳密度地区(0.05 kg/kWh)的排放量仅占0.1%,突显了区域能源结构对减排的关键作用。分析发现,全球大部分高算力模型部署在碳强度超过0.3 kg/kWh的区域。例如,美国主导的GPT-3在训练阶段产生的碳排放显著高于同等算力下瑞典数据中心的碳排放,这种地域失衡同样揭示了由数据中心负载迁移带来的显著减排潜力。
2、大语言模型的行业影响:行业垂直大模型的能耗特性更值得关注。其中,金融行业以192.88 GWh的能耗位居榜首,医疗行业虽然经济规模仅为金融的6.7%,但因医学影像数据的开放性和模型迭代需求,其能耗高达155.90 GWh。法律行业则因案情分析的复杂逻辑推理、数据隐私保护以及高时效性需求,导致其单位经济产值能耗是教育行业的7倍。这些差异表明,优化行业特定的数据处理模式可能比单纯提升硬件效率更具减排价值。
3、大语言模型的未来影响预测:考虑模型的开/闭源、参数规模、训练语料、日访问次数以及碳强度等因素,本文设计不同情景来预测未来十年大语言模型的碳足迹。结果显示,在所有情景下,大语言模型的年碳排放和能耗都将稳步上升。预计到2035年,大语言模型的年度碳排放可能达到0.18亿至2.46亿吨,年度能耗或达404.77 TWh至447.16 TWh。分析发现,开源情景下的碳排放和能耗水平均明显低于闭源情景,凸显了数据共享对降低环境影响的重要作用。此外,在低碳强度情景下,由于采用了更清洁的能源,大语言模型的碳排放显著降低。最后,若能实施开源数据共享、低碳能源转型以及二者结合等措施,累计到2035年可分别削减0.23亿吨、2.26亿吨以及2.28亿吨的碳排放。反之,如果不加干预,2035年大语言模型的年度碳排或达2.46亿吨。
该研究工作的成果“Tracking the Carbon Footprint of Global Generative Artificial Intelligence”近期已正式发表于Cell系列期刊The Innovation(IF 33.2)上,论文的共同第一作者是新能源电力系统全国重点实验室丁肇豪教授,新能源电力系统全国重点实验室是论文第一完成单位。该研究工作得到了国家重点研发计划、国家自然科学基金等项目资助。
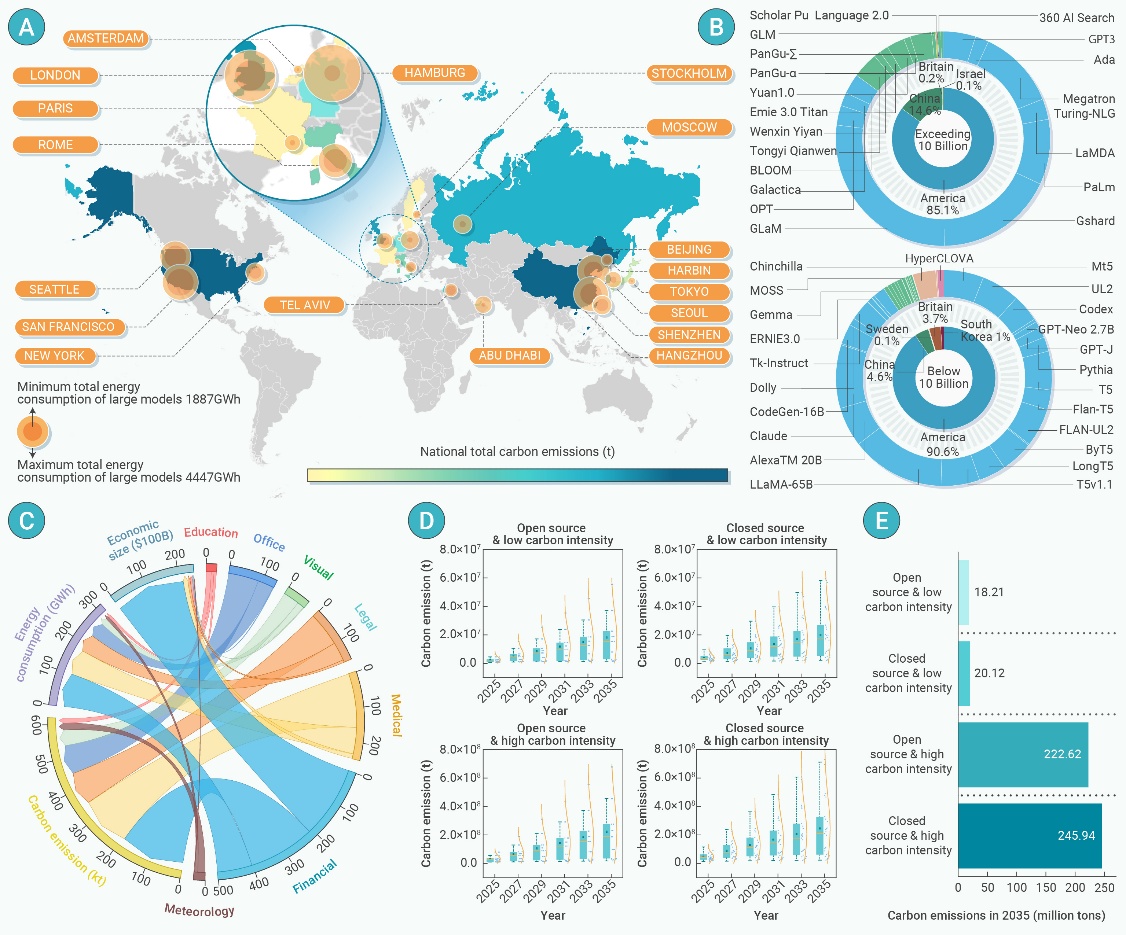
▲图一 全球大语言模型的能耗和碳足迹量化结果
Reference:Zhaohao Ding, Jianxiao Wang, Yiyang Song, Xiaokang Zheng, Guannan He, Xiupeng Chen, Tiance Zhang, Wei-Jen Lee and Jie Song. " Tracking the Carbon Footprint of Global Generative Artificial Intelligence" in The Innovation, p. 100866, 2025.DOI: 10.1016/j.xinn.2025.100866.